Overview
Data Theorem provides several integrations that collect information about your GKE deployments to help you manage your Kubernetes security posture. Additionally, like the data collected from all Data Theorem integrations, we send your GKE information to our analyzer to build a deep, full-stack understanding of your applications and resources they rely on.
The following integrations collect KSPM information:
GCP Account Integration
GCP Load Balancer Log Analysis Integration
Kubernetes In-Cluster Helm Chart Integration
KSPM Integrations
GCP Account Integration
The close integration of GKE and Google Cloud means that just by onboarding your GCP account we good visibility into your GKE clusters and the GCP resources they use.
How to enable this integration: https://datatheorem.atlassian.net/wiki/x/AoBQAg
GCP Load Balancer Log Analysis Integration
The Data Theorem GCP Load Balancer integration forwarding HTTP request logs from your GCP load balancers to a log sink that publishes HTTP request metadata to a Data Theorem Pub/Sub queue.
Cloud Logging Sinks can be created at multiple levels within GCP. Where the sink is created determines which logs it is able to forward: if the sink is created within a project, it will only be able to forward logs from that project. If the sink is created at the organization level or in a folder containing gcp projects, then it will be able to forward logs from any project within that organization or that folder.
Data Theorem strongly recommends creating the sink at the organization level to maximize discovery, and to then use the sink’s log filter to limit which logs are sent to Data Theorem.
Pre-requisites
Make sure that
Loggingis enabled on the Load Balancer Backend Service ConfigurationCheck this link for more information on how to enable Logging on the Load Balancer Backend Service
Create a Cloud Logging Sink
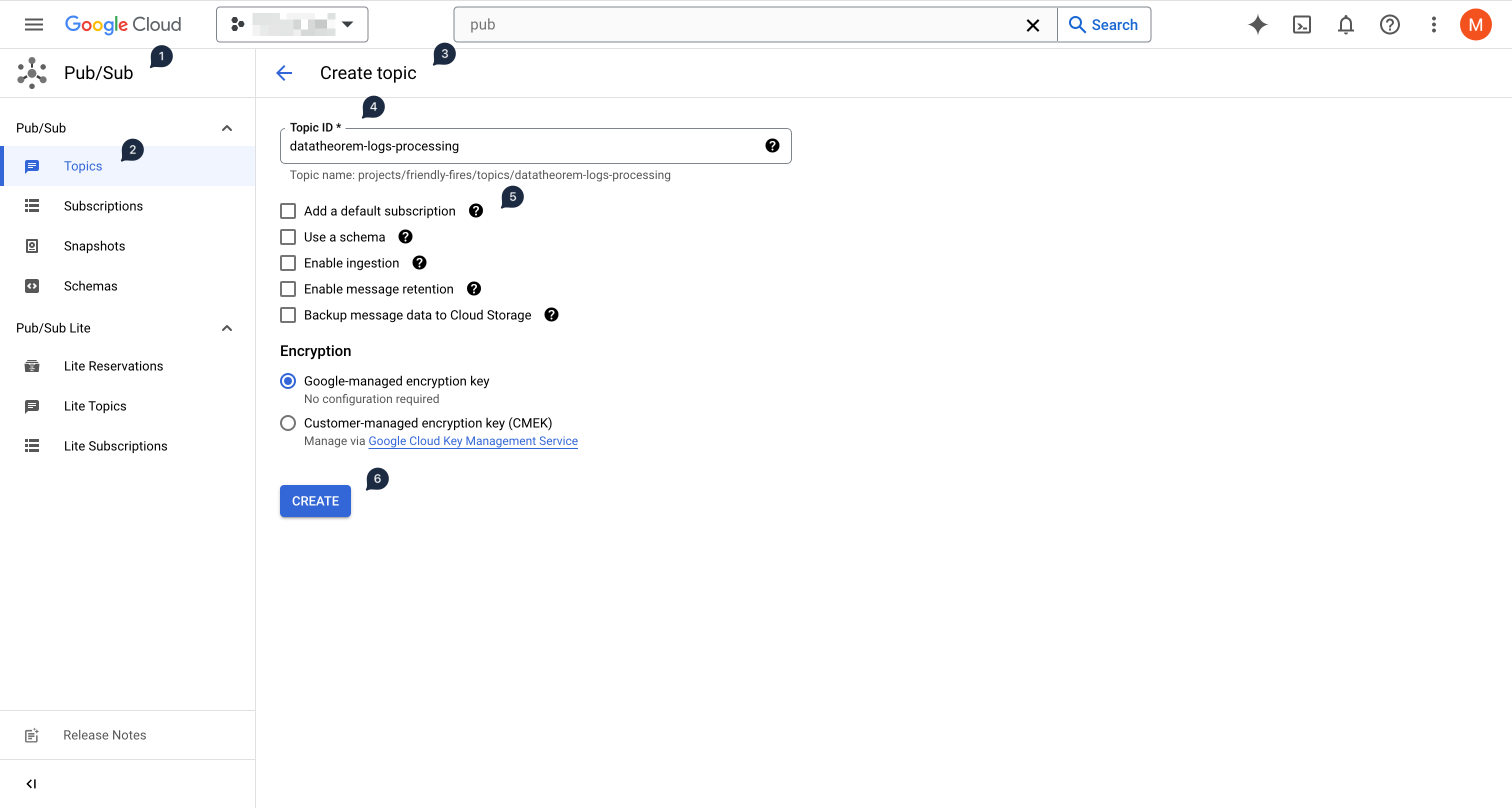
First, create a Pub/Sub topic in a project that will be used by the logs routing sink:
In the GCP console, switch to the project where you will create the Pub/Sub topic
If creating a logs routing sink at the organization or folder level, this should be your Data Theorem integration project
Otherwise it can be in the same project as where you plan to create the sink
Using the left-hand side menu, select Pub/Sub (in the Analytics section), and then select Topics
Click on Create Topic
Use
datatheorem-logs-processingas the topic ID, and uncheck "Add a default subscription"No other options are needed
Click Create to create the topic
Next, create the logs routing sink:
If creating the sink at the organization (or folder) level, switch from the project to your organization (or folder)
Using the left-hand side menu, select Logging (in the Observability section), then within the Configure subsection, select Log router
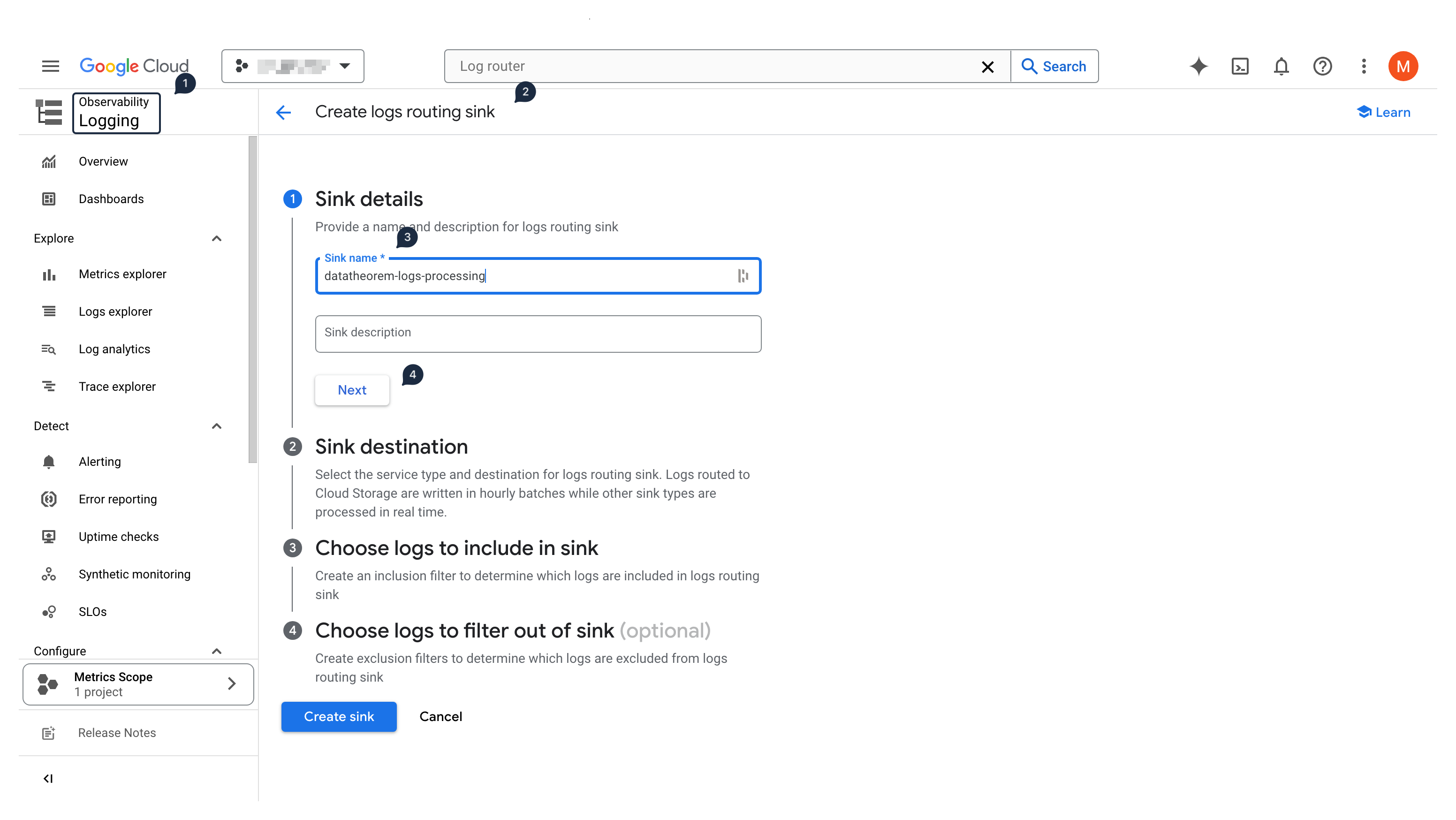
Click on Create Sink
In the Sink details section, input
datatheorem-logs-processingas the sink name, and click NextYou will have to fill in the full ID of the sink destination. For a Pub/Sub topic, it must be formatted as (but replace the
[PROJECT_ID]and[TOPIC_ID]with the topic's information):pubsub.googleapis.com/projects/[PROJECT_ID]/topics/[TOPIC_ID]Click Next
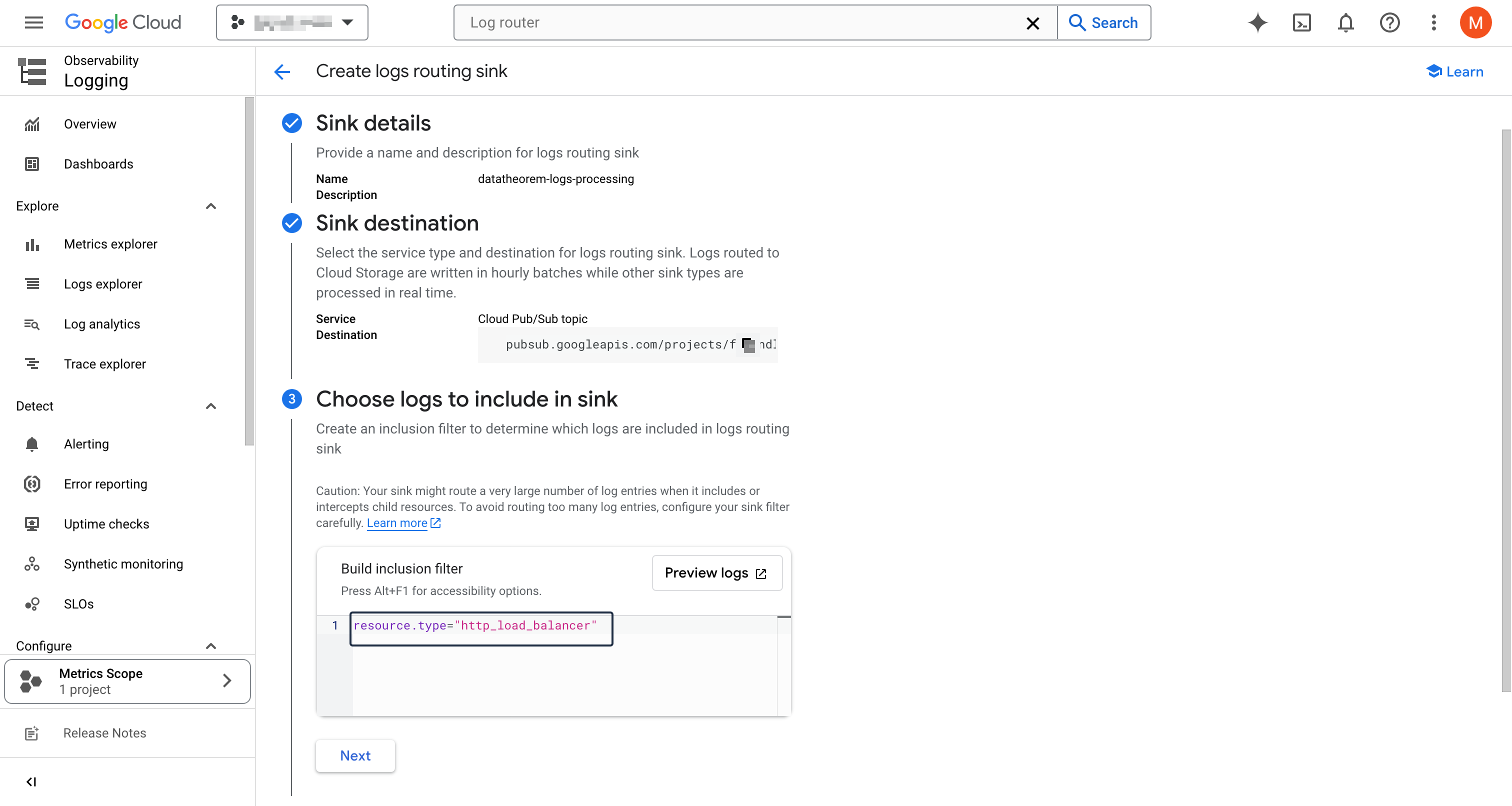
In the Choose logs to include section, add the following inclusion filter:
resource.type="http_load_balancer"You can click on Preview logs to see which logs will be included
Complete the sink creation by clicking on Create sink
Create a Service Account
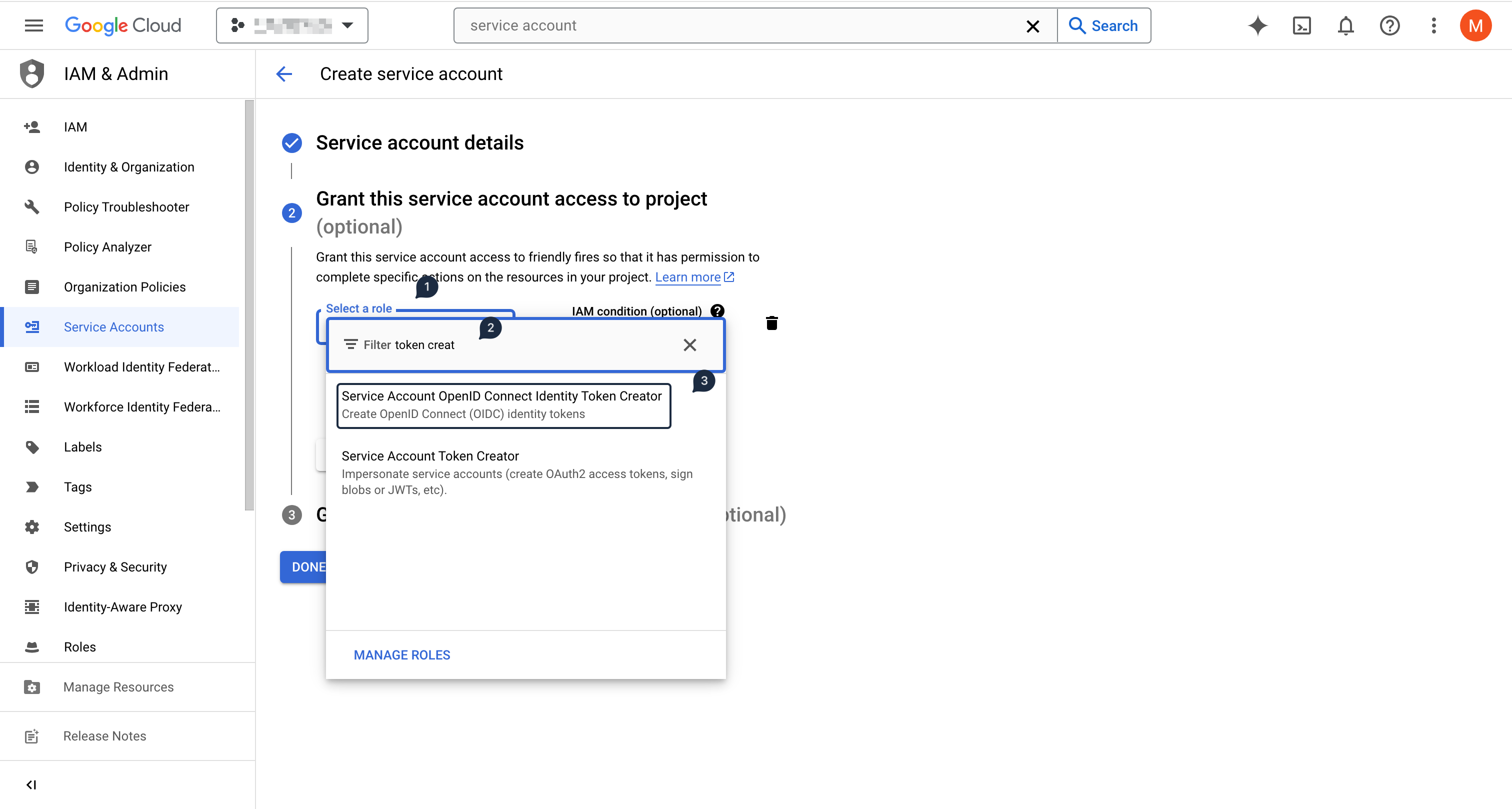
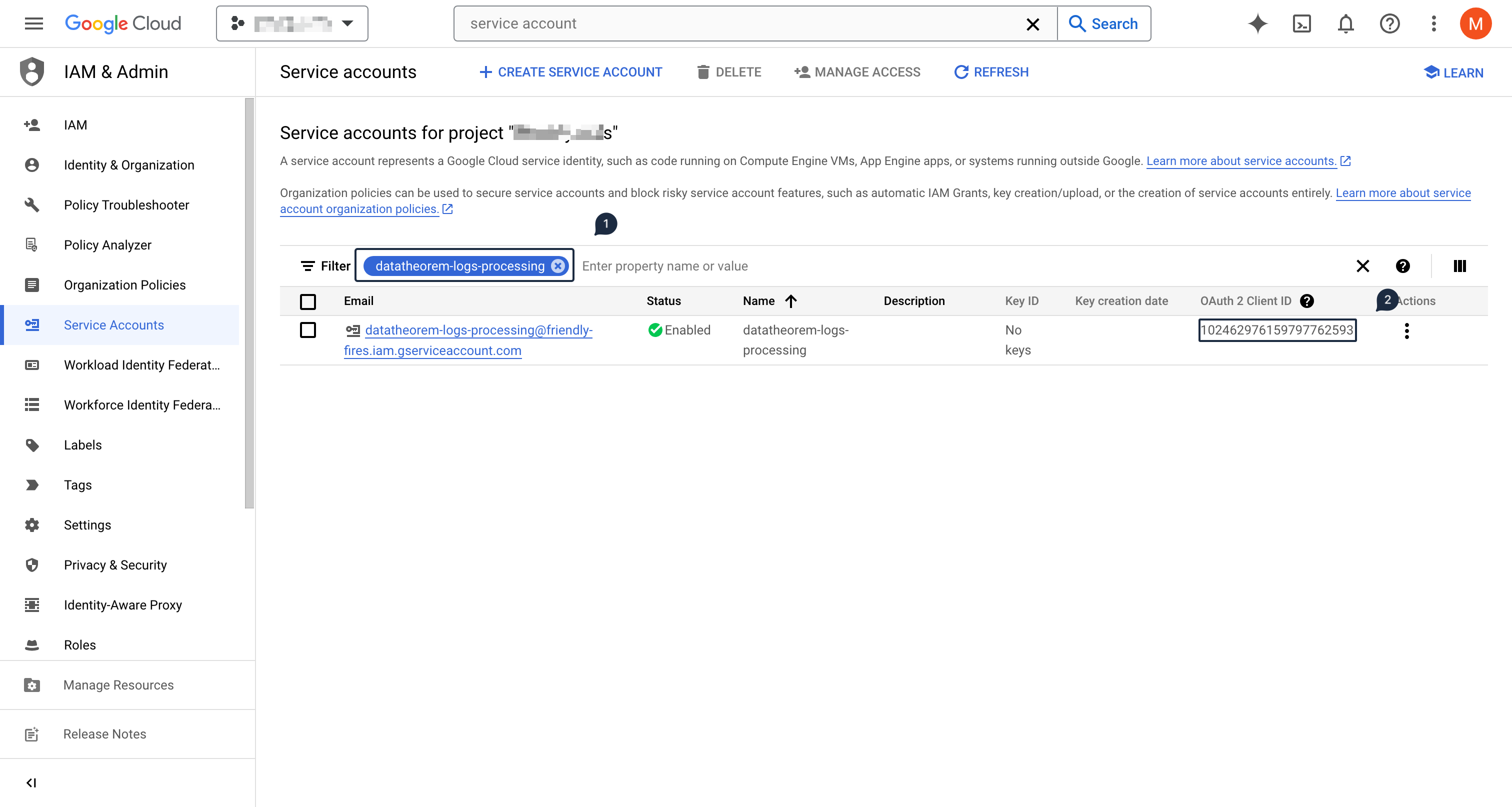
Create a new Service Account that will be used to authenticate the forwarded logs
In the GCP on console, switch back to the GCP project where the Pub/Sub topic was created
Then using the left-hand side menu, select IAM & Admin section, and then select Service Accounts
Click on Create Service Account at the top
In the Service account details section, input
datatheorem-logs-processingas the nameThen click on CREATE AND CONTINUE
In the Grant this service account access to project section, grant the
Service Account OpenID Connect Identity Token CreatorpermissionThis will allow Pub/Sub to generate OIDC tokens that will be used to authenticate requests
Complete the service account creation by clicking on Done
On the service account listing, above the table, input
datatheorem-logs-processingto retrieve the newly created service accountCopy the value from the OAuth 2 Client ID column and register it below
Create a Pub/Sub subscription
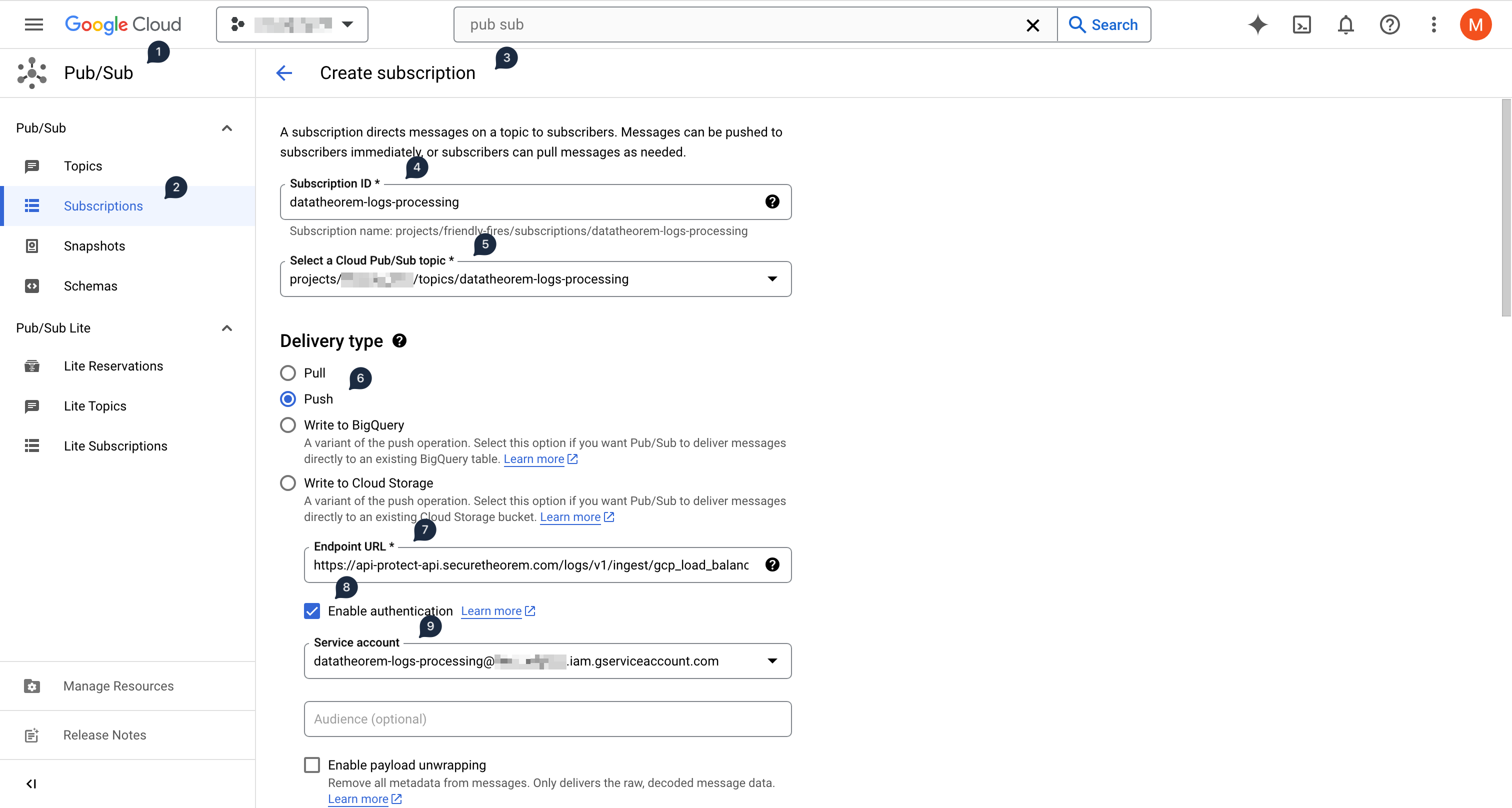
In the GCP console, in the GCP project where the Pub/Sub topic was created
Using the left-hand side menu, select Pub/Sub (in the Analytics section), then within the PUB/SUB subsection, select Subscriptions
Click on CREATE SUBSCRIPTION at the top
Input
datatheorem-logs-processingas the subscription IDClick on Select a Cloud Pub/Sub topic and input
datatheoremto filter the previously created Pub/Sub topicIn the Delivery type section, select Push
In the Endpoint URL text box, input
https://api-protect-api.securetheorem.com/logs/v1/ingest/gcp_load_balancersClick on the Enable Authentication checkbox below the Endpoint URL, and select the previously created service account
In the Retry policy section at the bottom, change the retry policy in the subscription to exponential backoff instead of immediate retry
Complete the Pub/Sub subscription creation by clicking on CREATE
Kubernetes In-Cluster Helm Chart Integration
Overview
This integration uses a Helm chart to create a discovery deployment in the datatheorem namespace in your Kubernetes cluster. The deployment is not “in-line” for any of your cluster’s services. The application is stateless and designed to consume almost no resources, and it should not require any autoscaling.
It uses the datatheorem-service-account bound to the datatheorem-cluster-role with the following permissions for read-only access on a limited set of cluster resources:
rules:
- apiGroups:
- "*"
resources:
- deployments
- pods/log
- pods
- services
- endpoints
- persistentvolumeclaims
- ingresses
- gateways
verbs:
- list
- get
- watch
Installation
Step 1 : Extract all the items which you should receive during the onboarding process.
unzip DataTheorem-APIProtect-K8S_PROTECT.zip
Step 2 : Verify you are configured for the correct kubernetes cluster
kubectl config current-context
Step 3 : Install API Protect
Add mirroring to the chosen endpoint. This step must be repeated for each endpoint.
helm install k8s-protect \
./k8s-protect \
--create-namespace \
--namespace datatheorem \
--wait
Step 5 : Verify the deployment
It should look something like this
helm list -n datatheorem NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION k8s-protect datatheorem 1 2023-06-20 11:56:08.223009524 +0100 CET deployed k8s_protect-1.0.0 1.0.5
Test the deployment
helm test -n datatheorem k8s-protect
Finished.
Un-Installation should it be required
helm uninstall -n datatheorem k8s-protect